On Multi-Set Hashing
Designing a hash function where the order of inputs doesn’t matter is surprisingly easy.
The Problem
The other day, I got curious enough to ask a question on Twitter:
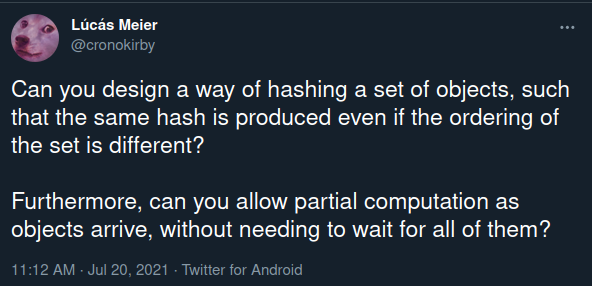
A typical hash function takes some data, usually just bytes, and outputs a succint digest of bits. A slight change to the data creates a large change in the digest.
Here, I’m asking if you can design a hash function for a set of objects. The order you hash the objects in shouldn’t matter. For example,
$$ H(\{a, b, c\}) $$
should return the same digest as:
$$ H(\{c, a, b\}) $$
A simple solution is to sort your objects before passing them to the hash function. For example, you’d sort $\{c, a, b\}$ to get the ordering $\{a, b, c\}$, and then pass that to the hash function. The initial ordering no longer matters, because you convert to a standard ordering before using the hash function.
Hash functions can work incrementally. If you want to hash a 2GB file, you don’t need to keep the whole file in memory. Instead, you can feed the hash function small chunks of the file, and end up with the same result as feeding in the entire 2GB of data at once.
Having to sort our objects before feeding them into the hash function loses this incremental property. We have to keep a large sorted collection around until we see all the objects.
What I was looking for in this tweet was a hash function that could accept objects directly as they arrived. The final would only depend on which objects they arrived, and not on their ordering.
We could also extend this function to multi-sets, where each object can appear multiple times. We’d want the same incremental property, of course. Our hash function would care only about which objects it sees, and how many times it sees them.
I was genuinely stumped on this problem for a while.
Thankfully, Samir raised my awareness to a paper [1] addressing this exact problem!
Some Approaches
The paper presents a few different hash functions. They’re surprisingly simple, and can be easily built up from first principles.
The general approach to hashing a collection of objects starts with a hash function $H$ for individual objects. Then, we can construct a collection hashing function $\mathcal{H}$ by hashing each object with $H$, and combining the results in some way.
XOR Hashing
Since hashes are just strings of bits, the simplest way of combining them is to use the xor ($\oplus$) operation:
$$ \mathcal{H}(S) := \bigoplus_{x \in S} H(x) $$
For example, to hash the set $\{a, b, c\}$ we would calculate:
$$ H(a) \oplus H(b) \oplus H(c) $$
Since $\oplus$ is commutative, this satisfies the incremental properties we want. As we encounter each new object, we can simply hash it, and then xor the hash into our current state.
Unfortunately, this hash function doesn’t work with multi-sets. For example, if we have the set $\{a, a\}$, then our hash is $H(a) \oplus H(a) = 0$. This is the same as hashing an empty set, or hashing $\{b, b\}$, and many other examples. Allowing multi-sets makes for easy collisions.
This is a minor issue. We can simply restrict our hash function to work on sets, like my original tweet asked for.
A larger problem is that it’s easy to create a collision with any hash.
You can see the set of bit strings $\{0, 1\}^n$ as a vector space $\mathbb{F}_2^n$. Vector addition $+$ corresponds to $\oplus$. An intuitive fact, which I won’t bother to prove, is that with $\approx 2n$ random vectors in this space, you have an overwhelming probability of being able to form a basis using some of these vectors. Given a basis $h_1, \ldots, h_n$, any other vector $v$ can be written
$$ v = \sum_{i \in I} h_i $$
for some subset $I$ of $\{1, \ldots, N\}$.
In other words, with approximately $2n$ hashes, we can write any other hash as the $\oplus$ of a subset of these hashes.
More concretely, you first calculate $H(x)$ for $\approx 2n$ objects, which then lets you create collisions for any hash value, by choosing the appropriate subset of these objects.
The solution is to augment this hash with a nonce, so that you can’t build up this basis in advance.
We use two domain separated hashes $H(0, \cdot)$, and $H(1, \cdot)$, and define our new set hashing function as:
$$ \mathcal{H}(S) := \rho \ ||\ (H(0, \rho) \oplus \bigoplus_{x \in S} H(, 1x)) $$
where $\rho$ is a nonce incremented, or generated randomly, each time we use the hash function.
$H(0, \cdot)$ and $H(1, \cdot)$ can be built from $H$ in different ways, such as built-in key derivation functions that accept a context, like BLAKE3, or HMAC modes, etc. The important thing is that $\rho$ will never collide with the objects we’re hashing, because of the domain separation.
This tweak means that comparing two hashes isn’t just a matter of equality, since the nonces will be different. To check if $\rho_1 \ ||\ h_1 = \rho_2 \ ||\ h_2$, we verify:
$$ h_1 \oplus H(0, \rho_1) = h_2 \oplus H(0, \rho_2) $$
Unfortunately, there’s still a little issue. Since the function $H$ is known, we can create collisions once again, simply by producing hashes with a nonce of $0$. We could also tweak our collision production for a specific nonce of our choosing.
The somewhat dislikeable approach chosen by the paper is to use a keyed hash function $H_k$ instead. Without the key, we’re unable to calculate the hash in advance, and thus unable to produce our collision basis.
What makes this incovenient is that you now need a key to verify the hash function as well, which is quite a departure from the original goal we set out.
Group Hashing
Thankfully, there’s a much more elegant scheme, which works for multi-sets, and doesn’t require a keyed hash, like our previous approach.
The extra primitive we need is an abelian group $\mathbb{G}$, with generator $G$ and order $q$, such that the discrete logarithm problem is hard. That is to say, given an element $k \cdot G$, finding $k$ is very difficult.
Examples include the multiplicative group of a field $\mathbb{F}_p^*$, or the group of a points on an elliptic curve $E(\mathbb{F}_p)$.
We also need a hash function $H$, taking arbitrary bytes, and returning an element of our group.
We can then define a hash function for multi-sets as follows:
$$ \mathcal{H}(S) := \sum_{x \in S} m(x) \cdot H(x) $$
where $m(x)$ is the number of times $x$ appears in the multi-set $S$. This quantity is commonly referred to as the multiplicity of $x$.
This is clearly correct, because addition in our group is commutative. We also have the property that $a \cdot H + b \cdot H = (a + b) \cdot H$, for any element $H$. This means that we can hash an element appearing multiple times with different groupings, and still get the same result.
It’s also clear how this function is incremental. The current state of our hash is an element $P$ of our group. To add in a new object $x$, our new state becomes $P + H(x)$. This allows us to calculate our hash as new objects arrive, without caring about the order in which they arrive.
This is secure because of two properties of the group. The first reason is that because we have a group, adding a random element $K$ perfectly masks any other element $M$. Given $C = K + M$, for any chosen element $M$, the element $K = C - M$ satisfies this equation. There’s always a random mask that could turn $M$ into $C$, regardless of what $M$ is. This means that knowing $C$ gives us no information about $M$, if we don’t know $K$.
The other reason is that the discrete logarithm is hard. This means that if we observe $m(x) \cdot H(x)$, we can’t figure out what $m(x)$ was.
One little caveat is that since our group has order $q$, then if two integers are congruent mod $q$, i.e. $a \equiv b \mod q$, then $a \cdot G = b \cdot G$. This means that we can easily create collisions, by choosing sets with the same multiplicities mod $q$. For example, the set $\{x\}$, and the set $\{x, \ldots, x\}$ $q + 1$ times.
We can get around this by restricting multiplicities to be $< q$. This isn’t a big restriction because $q$ usually has at least $250$ bits or so, which is an overwhelmingly large multiplicity.
A Concrete Implementation
This was such a simple idea that I wanted to try my hand at implementing it. To do this, I had to choose a concrete group $\mathbb{G}$. I ended up going with Ristretto, a prime order Elliptic Curve group based on Curve25519, mainly because the Rust implementation had a convenient function to convert from a 512 bit hash to a point on the curve.
I also think that having a group that isn’t of prime order might lead to potential issues with collisions, but I haven’t thought all that much about it. Regardless, better safe than sorry.
It only took me two evenings to code up, and I ended up releasing the hash function as a tiny crate. The source code is also available, as usual.
One neat thing about the implementation is that the hash function works using any 512 bit hash as a primitive. In the examples, I’ve used SHA-512, but you could use BLAKE3 too, for example.
The API is pretty straightforward. For example, to hash the set $\{\text{cat}, \text{cat}, \text{dog}, \text{dog}\}$, you’d do:
let mut hash = RistrettoHash::<Sha512>::default();
hash.add(b"cat", 2);
hash.add(b"dog", 2);
Of course, you could hash things in a different order, and with a different grouping, but still get the same result:
let mut hash = RistrettoHash::<Sha512>::default();
hash.add(b"dog", 1);
hash.add(b"cat", 1);
hash.add(b"cat", 1);
hash.add(b"dog", 1);
There’s not much else I have to say. If this looks interesting, you might want to check out the crate, or read the code, which have ample documentation.
Conclusion
I like this solution, because it’s so obvious that you forget how the question was ever unsolved to begin with. But really, when I first asked the question, I was genuinely stumped. Reading that paper and stumbling upon the group solution was a kind of eureka moment.
Hopefully I’ve shared some of that with you today.