On Strings in Compilers
I’ve been thinking recently about handling strings and names in compilers in a more principled way, and I think I’ve come up with a nice way of doing this.
This is just a short post about some of the problems involved with strings and names in compilers, and a nice solution I’ve arrived on after writing a few compilers.
The Problem
When writing a compiler, you need to be able to work with strings of characters present in the source code. There are two main sources of strings in the compiler:
- String literals, like
"foo" - Identifiers, like the
xinvar x = 3
You want to represent programs using a syntax tree, and so your tree needs to be able to store these strings, in some way.
Now, the naive approach is just to store the string verbatim. Whenever you have a string literal, or some kind of identifier, you just store the characters of that string directly in the AST.
This actually works out just fine, and is quite convenient in managed languages like Java, or Python, where it’s no problem at all to move strings around in your AST.
Recently, I’ve been working in Rust on a compiler, and there it’s much nicer to avoid storing Strings in the AST directly, to allow your tree nodes to be easily copyable, and to make comparison much faster.
Interning Strings
A good solution to this first problem is to intern strings. The way this works is that instead of simply storing our strings directly in the AST:
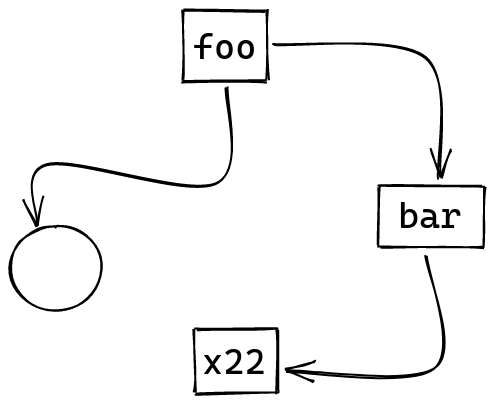
We instead create a unique identifier for each string, and then use those identifiers instead of the strings:
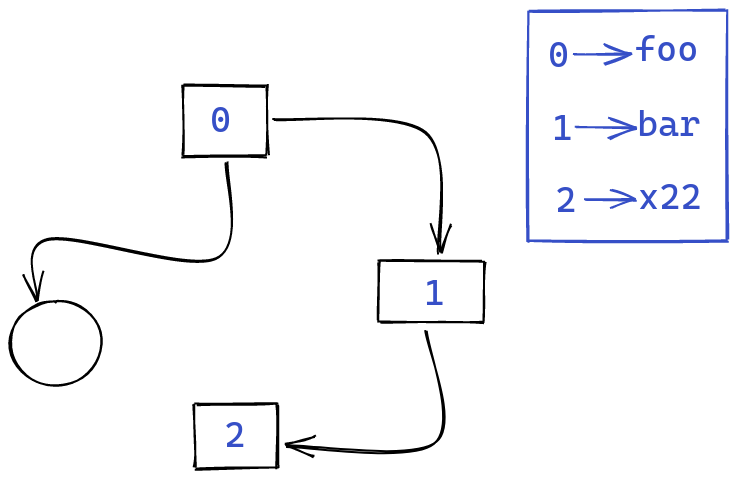
A first advantage of this approach is that our AST is now much lighter. Instead of storing big chunks of data, which aren’t easily copyable, we can instead work with small identifiers.
Using these identifiers also makes comparing much easier, since comparing an integer is much faster than comparing a full string.
Another emergent advantage of this approach, where each unique string has an identifiers, is that we can save on space if a string is repeated.
For example, a program like:
foo + foo * foo
Would have us avoid storing the string foo multiple times in our AST:
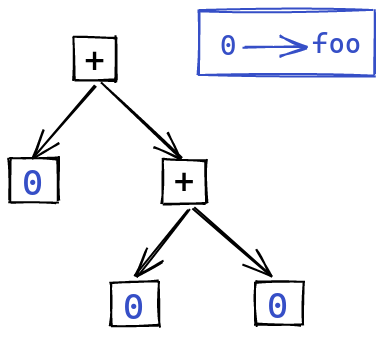
One big disadvantage to this approach is that we need a bit more infrastructure to pretty print our AST. Before, we had access to the string directly inside of the AST. Now, we need to make sure we have access to this table when printing out the AST, which is a bit more cumbersome.
Resolving Names
Now, when we compare two identifiers with this scheme, we’re just comparing the underlying strings. The problem is that the scoping rules for most languages allow shadowing.
Take this example:
let x = 2;
let y = 34;
{
let x = 3;
// 3
console.log(x);
}
In the inner scope, we shadow the outer variable, with a new one.
The x we’re referring to inside of that block is different from the x
outside of the block. But, since both identifiers have the same string
as a name, they would be equal under our current scheme.
Now, the approach I’ve used many times, but am slowly moving away from, is to use a data structure that reflects this scoping structure. Instead of having a simple table of identifiers to properties, you instead have a stack of tables, one for each scope. When you enter a new scope, you create a new table, and you pop it off when you exit that scope.
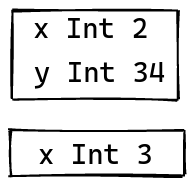
With this approach, you can keep track of different variables in a way that respects shadowing. Whenever you enter a new scope, you have a new table, and variables defined in this scope shadow all of the tables beneath it.
If you want to do some kind of substitution, like replacing a variable with some value, then you need to use a data structure like this, in order to keep track of new variables that might be shadowing the substitution you want to do.
For example, if you want to replace x with 42 in the following snippet:
let y = x * x;
{
let x = 3;
y += x;
}
Then you don’t want to replace the x defined in the inner block with 42,
so you need to use some kind of scoped data structure as you work out your substitution.
Unique Names
A better approach that I’ve been warming up to recently is to instead isolate all of this scoping logic into a single pass of the compiler. This pass is usually present in some form, and serves to make sure that variables aren’t used before being defined, and functions that don’t exist aren’t called, and other things like that.
The idea is to use this pass to assign a unique identifier for every logical variable.
So, if I have a case of shadowing:
let x = 3;
let y = x * x;
{
let x = 4;
y += x;
}
Then I’d have a different identifier for the second x, since it represents a different
variable:
let $0 = 3;
let $1 = $0 * $0;
{
let $2 = 4;
$1 += $2;
}
One immediate advantage of this approach is that if two identifiers are equal, then they refer to the exact same variable.
This also makes substitution much simpler. Instead of needing to worry about scoping, I now have a flat table of variables, and can simply replace every occurrence of some identifier with the value, because I know that shadowing never happens.
Since each variable has a unique identifier, you can also now have a nice global table of variable properties, like their type and initial value, if you’d like, without worrying about needing a scoped data structure for shadowing reasons.
You can also extend this scheme to functions, as well. You can even work out module resolution and other things like that at this stage, and then work with simple flat identifiers from that point on.
Conclusion
In brief, my current approach is to never have strings present in the AST at all. Instead, you start with interned strings, using a unique tag for each string in the source code. Then, you want to do some kind of name analysis pass somewhat early, in which you assign to each logically different object (variables, functions, etc.) a unique identifier, making subsequent work with these objects much simpler.
I think this approach is quite elegant, and I kind of wish I’d settled on it a lot sooner.