On Deep Immutability
This post is about the different ways objects can be immutable and mutable in programming languages, why deep immutability is what we really want, and a path towards implementing that in higher level languages.
Why Immutability?
Immutability is about declaring that certain values in our program don’t change. We can declare certain variables as immutable, and then the compiler should prevent us modifying that value in any way.
This allows us to state our intentions clearly. Even if the compiler didn’t enforce
this property, it would be useful to tell other programmers about our program.
We would see that a variable is marked as immutable, and expect the variable
not to be modified later.
This can help the compiler optimize our code. If it knows that some variable is immutable, it can take that into account.
Compiler verification of this property helps prevent bugs. If we have two similarly named variables:
immutable x := 3
x2 := 4
++x
then the accidentally modifying the wrong one is prevented, since the compiler makes sure that we can’t modify and immutable variable.
Many variables are only used once, and it’s better for them to be immutable. It’s a good idea to avoid giving extra permissions where it’s not necessary. Annotating variables as mutable when it’s not necessary can be confusing for readers, and introduce potential bugs.
Where we are
Most languages nowadays have variables as mutable by default, and
allow us to annotate variables as immutable explicitly. We have final in Java, for example.
Other languages make us choose between mutable and immutable, both requiring explicit declarations.
In JavaScript we have let (mutable), versus const (immutable).
Both of these are shallow. We can’t reassign an immutable variable, but we can change its contents:
const x = { a: 3 };
// Illegal
x = { a: 4 };
// Legal
x.a = 4;
This is not as much protection as we’d like to have.
Deep Immutability
A more useful property would be deep immutability. An immutable variable would not be reassignable, nor would we be able to modify any part of it, directly, or through methods.
Going back to our old snippet:
const x = { a: 3 };
// Illegal
x = { a: 4 };
// Illegal
x.a = 4;
both of these modifications are not illegal.
It makes sense for immutability to be deep. All of the reasons we have for wanting immutability don’t just apply to reassignment, but all modifications.
The full matrix
We’ve seen fully mutable, shallowly immutable, and deeply immutable variables so far. If we create a full matrix of these options, we get:
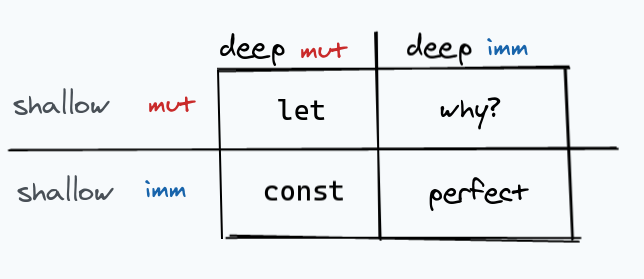
let and const occupy two familiar quadrants of this matrix, our ideal immutability
occupies a third, and a weird combination occupies the last.
Pointless Combinations
I think that two of the combinations we have in this matrix are actually not very useful, and shouldn’t really be included in programming languages.
Shallow Mutable, Deep Immutable
The first is the “why?” part of the quadrant. Variables that can be reassigned, but can’t be modified inside.
I can see the argument for economy of mechanism here. Sometimes we might only need to reassign a variable, but not actually mutate its insides. I’m going to contradict myself a bit, and say that this is rare enough to allow giving ourselves too many privileges, and making the variable completely mutable in this situation.
Shallow Immutable, Deep Mutable
This one is more controversial, since this is the way most languages provide
an immutable modifier. I think that this is always less useful than
a completely immutable variable.
The same contradiction with the economy of mechanism principle applies, in the rare case where we want to be able to modify deeply, but never reassign the variable.
Having a modifier, like nonreassignable (but perhaps less verbose) would be useful,
but I expect that most uses of const would really benefit from
saying deeplyimmutable instead. This would provide us with much stronger guarantess
about how a variable is used as well. Not only do we know it cannot be reassigned in this scope,
but no functions or methods using it can modify it either.
This is a much stronger, and much more useful guarantee than that of shallow immutability.
A Concrete Model
So far we’ve been talking about these things in the abstract, but how would you actually make this into a reasonable set of language features?
I’ve been thinking about making a programming language, or part of a language, using these features. I think I’ve gotten a reasonably useful model of how to do things.
Immutable by Default
Variables should be immutable by default. If you define a variable, then that should make the variable deeply immutable. It should not be reassignable, nor can we modify its contents, or pass it to functions that might modify it.
So, if we have:
x := 3
then that means immutable, as specified above.
This makes for a better default, for all of the reasons we went over at the start of the post.
This would also apply to function parameters:
fn foo(a, b) {
}
Here a and b are immutable, so they cannot be reassigned inside the function.
We can also pass in variables to this function that are themselves immutable, since
the parameters can’t be modified.
Explicit Mutability
We can also mark variables as explicitly mutable:
mut x := {a: 3}
This would allow us to reassign the variable, and modify its contents:
mut x := {a: 3}
x = {a: 4}
x.a = 5
Function parameters work in a similar way:
fn increment(mut x: Int) {
x += 2
}
Note that even though most other languages would copy the integer passed to this function, semantically we wouldn’t distinguish between primitve and reference types.
This program would indeed print 4:
mut y := 2
increment(y)
print(y)
Furthermore, we wouldn’t be allowed to pass an immutable
variable to the function increment, which demands its argument be mutable.
The Copy Model
We’ve described immutable and mutable variables in isolation, and mentioned that immutable variables can’t be passed as mutable arguments to functions, but there are other interactions we want to describe. For example, can we assign immutable variables to mutable ones?
x := 2
mut y := x
z := y
One simple model that captures the semantics we want is that every assignment to or from an immutable variable acts as if we had copied that variable, deeply. Assignments between mutable variables act as if we’re copying a pointer to that variable.
So, in:
mut y := 1
mut z := y
y += 1
print(z)
we would end up printing 2, since z and y refer to the same object.
However, if we have:
mut y := 1
z := y
y += 1
print(z)
We get 1. The assignment to z is an assignment to an immutable variable,
and so acts as if we had copied that variable.
These semantics also apply to function parameters, with a single caveat we mentioned earlier: you can’t pass immutable variables to mutable parameters. Instead you need a temporary to capture potential modifications:
fn inc(mut x) {
x += 1
}
y := 3
mut y2 := y
inc(y2)
// 4
print(y2)
Futhermore, assigning to an immutable parameter would act as if we had copied.
fn foo(x) {
}
mut z := 3
// copy
foo(z)
Optimizations
Of course this model takes many more liberties than are absolutely necessary, but any optimizations we do, as I’ve started to mention in the last note, will respect these semantics absolutely. Of course, you can do sophisticated analysis to find out where copies are actually unnecessary.
The first optimization is that in basically all cases, immutable variables can share a reference:
x := Foo {1, 2}
// Same variable in memory
y := x
Because x’s object cannot ever be modified, we can share it with y, and run into no issues.
Another optimization is observing that a variable doesn’t actually need to be mutable, at which point we can remove the qualifier, which might lead to cascading optimizations
fn program() {
x := Foo { 1, 2 }
// y never mutated, make immutable, elide copy
mut y := x
print(y.0)
}
We might also elide a copy to a mutable location, if we can show that the immutable variable is never used again:
fn program() {
x := 3
// x never used again, elide copy
mut z := x
z += 1
// 4
print(z)
}
This starts to get a bit complicated, because now we need to look at usages, and this can get intractable relatively quickly if we start looking into function calls. We could inspect the function call itself to see how things are used and gather further optimizations.
Other Questions
One question I’ve had is how this interacts with concurrency. If you create some kind of channel abstraction,
it’s clear the you should have fn send(x: X), and that should be immutable. This function might need to be
a primitive, or marked in some way that the compiler doesn’t try to do any copy eliding, because it really has very little guarantee
about how the value is used on the other end.
With a primitive like this, you basically have to do two copies on each end, if you’re moving to and from mutable locations. One thing you might want to introduce is some model of “moving” a variable. This way the other thread gains ownership of it, and doesn’t copy the variable, you just send a pointer along, but you’re no longer allowed to use that variable in any way on your side.
You might also want some kind of “resource” variable to encapsulate things like file handles, mutex handles, for determinstic resource cleanup. This would interact heavily with this simplified form of ownership. I haven’t managed to find a way to do this that wasn’t exceedingly ad hoc though.
Conclusion
Overall, I think the defaults defined in this prototypical model are solid, and I like the simplicity of the theoretical model, but it seems that many optimizations you’d want or need to have, related to copy elision, would require basically a hidden form of ownership system to get right. See the whole shenanigans about passing an immutable variable to a function, which then returns a new struct containing that value.
I plan to try and flesh out a language using these ideas a bit more concretely in the relatively near (read: far) future.