Encoding the Naturals
In this post, we’ll cover 3 ways I know of encoding the natural numbers $\mathbb{N}$ in your standard functional language with recursive types and polymorphism. At least, these are the 3 most generalized ways of doing it. As we’ll see, some common encodings are just specific cases of a more general encoding.
Prerequisites
Some familiarity with defining data types in a functional-esque language might be helpful, but shouldn’t be strictly necessary. Understanding recursive data types and polymorphism is helpful as well. I use a bit of category theory (natural transformations) at one point, but you can just skim over that if the concept is alien to you.
$\mathbb{N}$, recursively
The natural numbers, mathematically, are the standard set of “counting numbers” we’re familiar with from preschool:
$${0, 1, 2, 3, 4, 5, \ldots}$$
This is an infinite set, going on forever, starting from the number $0$. The mathematical definition isn’t the concern of this post, but it can be interesting to think about how we might introduce the natural numbers into a system of mathematics. The main problem there is whether or not we need to basically accept the natural numbers as some axiomatic object that exists, or whether we can define it through some more fundamental construct.
In a programming language, we can translate finite sets of objects into a type pretty straightforwardly. For example, set $\mathbb{B} = {T, F}$ of booleans can easily be encoded as a sum type in Haskell:
data Bool = T | F
An element x of type Bool is either T :: Bool, or F :: Bool. Those are the only two ways to
construct a Bool.
We can map the same process to recreate any finite set in Haskell. Each element of the set becomes a constructor of the data type. Of course, there are sometimes better ways of doing this. For example, the cartesian product $\mathbb{B} \times \mathbb{B}$, concretely is:
$${(F, F), (F, T), (T, F), (T, T)}$$
Which, using the same translation, gives us:
data BxB = FF | FT | TF | TT
We could reuse the bool type we defined previously, and get the much less redundant:
data BxB = Both Bool Bool
Then Both T F, Both F T, ... would serve as our elements.
Anyways, the problem with $\mathbb{N}$ is that it is infinite. If we try to define something like:
data Nat = Zero | One | Two | ...
we can’t actually finish the process. Unfortunately (or inevitably), Haskell is not able
to understand what we mean by ... in this context. If we managed to do things this way,
then our datatype definition would have an “infinite” amount of information, but to construct
a Nat, you would only need a “finite” amount of information, the constructor to use.
We want to reverse this, to have a finite specification of Nat, allowing for “infinitely large”
combinations of the constructors.
The solution is to use a recursive definition:
data NatRec = Z | S NatRec
(We’ll call this one NatRec, to disambiguate this specific encoding from the ones we’ll see later).
Then Z, S Z, S (S Z), ... would be the elements of this type. By allowing for a recursive
type, we’ve managed to specify the shape of the data type in a finite way, but allow for an
infinite number of elements. Before, the burden was on the specifier of the type to provide
an infinite set of finite constructors. Now we have a finite set of constructors,
and the burden has shifted to whoever is constructing in arbitrarily large number to nest
provide an expression S (S (S (S ...))).
The element Z corresponds to $0$, and S m corresponds to $1 + m$.
We can define the standard ring structure ($+, *$) in a straightforward way:
(+) :: NatRec -> NatRec -> NatRec
Z + m = m
(S m) + n = S (m + n)
(*) :: NatRec -> NatRec -> NatRec
Z * m = Z
(S m) * n = n + m * n
It’s easy to see the correctness of these equations if we translate them to the familiar arithmetic. For addition, we have:
$$ 0 + m = m \newline (1 + m) + n = 1 + (m + n) $$
And for multiplication, we have:
$$ 0 * m = 0 \newline (1 + m) * n = n + m * n $$
The standard laws of a commutative rig (no negative numbers here) are sufficient to verify that these are true.
This is the most straightforward way to encode natural numbers, and if you’re trying to define this object
from scratch, probably the best way to do so. In practice, you’d want to use some kind of newtype over
Integer, the standard bignum type that Haskell provides. This would be a lot more efficient, but equivalent
to this encoding.
$\mathbb{N}$, Scott Encoded
The next technique we’ll use will be to take our recursive definition, and then
use scott encoding (sometimes called church encoding) in order to turn it into a
single function type, (a -> b) -> c -> ... instead of a sum type C a b ... | D c ....
Yoneda Lemma
This lemma is a profound result from category theory, but we only need a very specific
instance of it. The result we need is that for any specific type A, this type will be isomorphic
to forall x. (A -> x) -> x, where we need to place emphasis on the fact that the second function
type is polymorphic: it has to work for all types x. A is chosen in advance, and the function
can, and should, depend on what A is, but cannot depend on what x is.
We can actually prove that two types T1, T2 are isomorphic in Haskell, by providing functions
T1 -> T2, T2 -> T1, and then verifying that composing them in either order provides us with the identity function.
So, let’s look at the specific case we have here:
iso1 :: A -> ((A -> x) -> x)
iso1 a = \f -> f a
iso2 :: ((A -> x) -> x) -> A
iso2 h = h id
It’s easy to see that iso1 . iso2 = id, and iso2 . iso1 = id. Understanding this more philosophically
is not really necessary. The mechanistic definition is all we really need.
That being said, the way I like to think of this is as a kind of game. Both players agree on what A is.
Then one player chooses a value for x, and then provides a function A -> x. The other player needs
to respond with an x. Let’s call the first player the guesser, and the second the responder.
If I’m the responder, I can easily be able to answer all of the guesses by taking some initial value a :: A
as the game starts, and then whenever the guesser gives me some function, I can apply it
to that element a.
If I’m the guesser, then I have a strong hunch that the responder is doing nothing more than applying my guesses
to a secret element a :: A. I can figure out what this a is by providing the identity function.
Products Sums under Yoneda
So far, the presentation of this yoneda encoding is interesting, but doesn’t seem to
be all that different at a first glance. It seems that the only real way to end
up with a value of type (A -> x) -> x is to simply construct an a :: A, and then
use iso1.
But, this isn’t actually the case. This is because a consumer A -> x transforms sums into products,
and vice versa. What I mean by this is that if we look at a sum type data Y = L | R, and
then look at what a function Y -> x needs to do, we realize that it has to be able to handle both
L, and R. Conversely, if we have a way to handle each branch, we can handle
an element of the sum type. In fact, we can show the following isomorphism:
iso1 :: (Y -> x) -> (() -> x, () -> x)
iso1 f = (\() -> f L, \() -> f R)
iso2 :: (() -> x, () -> x) -> (Y -> x)
iso2 (fL, fR) = \y -> case y of
L -> fL ()
R -> fR ()
(x is the same as () -> x, but explicitly marking the constructors taking no arguments, it’s easier to
see how this might generalize if the constructors do take arguments)
Because of this, a function (Y -> x) -> x is nothing more than a function
(x, x) -> x
We see that L is equivalent to the function that picks the first argument, and R is equivalent
to the function that picks the second argument. Now this seems substantially different
than Y = L | R. (In fact, this is the Scott / Church encoding of a Boolean type).
The analogous transformation is already well known as currying:
iso1 :: ((A, B) -> x) -> (A -> B -> x)
iso1 f = \a -> \b -> f (a, b)
iso2 :: (A -> B -> x) -> ((A, B) -> x)
iso2 f = \(a, b) -> f a b
Scott Encoding
Scott encoding is nothing more than taking a data type D, representing it with
(D -> x) -> x (which we’ve proved to be isomorphic), and then applying the simplifying
rules for sum and product that we’ve seen.
As an example, take the following datatype:
data Y a b = Both a b | A a | B b
Applying this procedure we get:
data Y a b = Both a b | A a | B b
data ScottY a b = ScottY (forall x. (Y a b -> x) -> x)
data ScottY a b = ScottY (forall x. (Both a b | A a | B b -> x) -> x)
data ScottY a b = ScottY (forall x. (a -> b -> x, a -> x, b -> x) -> x)
The final definition is precisely what the scott encoded version of Y is.
Applying this to $\mathbb{N}$
The only potential problem with applying this to NatRec is that the type is recursive,
i.e. it references itself. But, we can just blindly apply the rules of scott encoding, using
a recursive definition without thinking about it:
data NatScott = NatScott (forall x. (x, NatScott -> x) -> x)
We can define the traditional constructors in terms of this encoding pretty straightforwardly:
zero :: NatScott
zero = NatScott (\(onZ, _) -> onZ)
succ :: NatScott -> NatScott
succ m = NatScott (\(_, onS) -> onS m)
This provides us with a straightforward isomorphism with NatRec:
iso1 :: NatRec -> NatScott
iso1 Z = zero
iso1 (S m) = succ (iso1 m)
iso2 :: NatScott -> NatRec
iso2 (NatScott f) = f (Z, S . iso2)
We could define addition and multiplication by converting to and from NatRec,
but it’s more fun to define it directly in terms of NatScott:
(+) :: NatScott -> NatScott -> NatScott
(NatScott f) + n = f (n, \m -> succ (m + n))
(*) :: NatScott -> NatScott -> NatScott
(NatScott f) * n = f (zero, \m -> n + m * n)
These two definitions make heavy use of the earlier definitions we had for NatRec, to
make things simpler.
Church Encoding
The more common encoding of the natural numbers as functions looks like this:
data NatChurch = NatChurch (forall x. (x -> x) -> (x -> x))
This is called the church encoding of the natural numbers, but is ambiguous with the scott encoding we’ve just defined. We’ll be figuring out why this works by first generalizing it.
$\mathbb{N}$ as a monoid
Mathmetically, a monoid is a set $M$ equipped with an operator $\bullet : M \times M \to M$, and an identity element $e \in M$. The axioms are:
associativity:
$$ a \bullet (b \bullet c) = (a \bullet b) \bullet c $$
identity:
$$ e \bullet a = a = a \bullet e $$
The natural numbers $\mathbb{N}$ along with addition $+$, form such a monoid, with $0$ acting as the identity element. In fact, the natural numbers are very special, because they have a generator. If we look at, say, $3$, then we can write $3 = 1 + 1 + 1$. Similarly, $5 = 1 + 1 + 1 + 1 + 1$, and in general:
$$ n = 1 + \cdots + 1 \quad (n \text{ times}) $$
Because of this, we say that $\mathbb{N}$ is generated by $1$. Now there are other monoids generated by some set of elements as well. For example, if we take $\mathbb{N}$, but with all elements modulo $3$, then $1$ will generate this group as well. But, we add the rule that $1 + 1 + 1 = 0$. $\mathbb{N}$ is freely generated in the sense that we don’t have any additional rules like $x \bullet y \bullet z = 0$.
We can also consider free monoids generated over more than a single element. In general, this looks like a list, with symbols drawn from a set, and no other rules besides concatenation. So:
$$
abbabbba \
babababa \
aaaa
$$
are all elements of the free monoid with two generators. The last element could also be seen as the element $1 + 1 + 1 + 1$ of $\mathbb{N}$ as well.
Induced Homomorphisms
One way to look at the free monoid over some set of generators is that it allows to build up statements involving the monoidal operation and elements taken from this set, but we can never reduce these statements beyond the rules that exist for all monoids.
So
$$ x(xyz) = (xx)(yz) $$
only because associativity is an axiom that all monoids must satisfy.
Some monoids might have additional rules, so:
$$ xxxx = x $$
holds in the integers modulo $3$, replacing $xx$ with $1 + 1$, of course.
So by relabelling $x \to 1$, we can interpret this abstract monoidal equation into a concrete equation that might mean something interesting.
More formally, if we have a set function $S \to M$, with $M$ a monoid, then this induces a morphism $\varphi : \langle S \rangle \to M$, (where $\langle S \rangle$ is the free monoid over a set of generators $S$) which respects the monoidal structure of $\langle S \rangle$. i.e. $\varphi(xy) = \varphi(x) \bullet \varphi(y)$ There’s a canonical way of making a set function $S \to \langle S \rangle$, simply mapping each symbol to the list containing that symbol by itself, so we end up with the following commuting diagram:
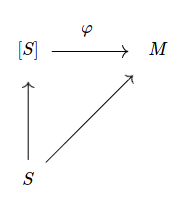
This induced morphism simply takes a list of symbols, replaces them using the mapping $S \to M$, and then connectes them using $\bullet$, the operation belonging to $M$.
So, if we take ${x, y}$ as a set of generators, and $\mathbb{N}$ as our monoid, then a mapping $x \mapsto 2, y \mapsto 5$ would mean that:
$$ xxyy \mapsto 2 + 2 + 5 + 5 \newline xyx \mapsto 2 + 5 + 2 \newline \mapsto 0 $$
(the empty string is part of the free monoid as well).
The Free Action
If we take the set with a single element ${1}$ (up to isomorphism :)), then a function ${1} \to M$ is nothing more than an element $m \in M$. The induced morphism then works like this:
$$ 1 + 1 \mapsto m \bullet m \newline 1 + \cdots + 1 \mapsto m \bullet \cdots \bullet m $$
So, given any element $m$, we can “multiply” it by a natural number $n \in \mathbb{N}$. Flipping things around, for a fixed natural number $n$, we get a map $M \to M$, mapping any element to its multiplication by $n$. This is a homomorphism, respecting the monoidal operation, and also has the very special property of commuting with any other homomorphism. That is to say:
$$ n \cdot \varphi(a) = \varphi(n \cdot a) $$
If you really like category, you’d be amazed to know that this exhibits a natural number as a natural transformation $1_{\bold{Mon}} \to 1_{\bold{Mon}}$. In fact, the natural numbers are isomorphic to these natural transformations
You can generalize this concept readily to other categories, seeing it this way. For example, if we do the same exercise over groups, we get $\mathbb{Z}$ instead!
Back to Haskell
Back down from category heaven, we have that a natural number is isomorphic to a function between
two monoids. We encode a function between monoids as Monoid m => m -> m. In Haskell, the monoid class
is (roughly) defined as:
class Monoid m where
mempty :: m
(<>) :: m -> m -> m
We thus have the natural definition with this encoding as:
data NatMon = NatMon (Monoid m => m -> m)
The standard constructors can be defined easily:
zero :: NatMon
zero = NatMon (\_ -> mempty)
succ :: NatMon -> NatMon
succ (NatMon f) = NatMon (\m -> m <> f m)
Let’s go ahead and define addition and multiplication, this time in a way that
doesn’t simply mirror what NatRec does:
(+) :: NatMon -> NatMon -> NatMon
(NatMon f) + (NatMon g) = NatMon (\m -> f m <> g m)
(*) :: NatMon -> NatMon -> NatMon
(NatMon f) * (NatMon g) = NatMon (f . g)
The fact that the second definition works is quite marvelous, and is stil strikingly beautiful to me. It’s interesting that multiplication over the natural numbers is entirely determined by function composition, seeing the natural numbers as the “universal” monoid homomorphism.
Now, let’s work on an isomorphism with the standard definition:
iso1 :: NatRec -> NatMon
iso1 Z = zero
iso1 (S m) = succ (iso1 m)
iso2 :: NatMon -> NatRec
iso2 (NatMon f) = f (S Z)
(Where we’ve provided a suitable monoid instance for NatRec using + and Z)
I find this isomorphism a lot more elegant than the scott encoding.
Back to Church Encoding
Let’s contrast this definition with that of church encoding:
data NatMon = NatMon (Monoid m => m -> m)
data NatChurch = NatChurch ((a -> a) -> (a -> a))
Now, these do look a bit similar. So similar, in fact, that one question comes to us immediately:
is (a -> a) a monoid? Well, yes! We can use composition (.), which is associative, and we always
have id :: a -> a, acting as the identity element. Because of this, we can see the church encoding
as nothing more than a specific case of the encoding in terms of a monoid homomorphism.
Personally, I find the general approach easier to understand philosophically, and prefer it to the church encoding. The advantage of the church encoding is that you don’t need to rely on the existence of the monoid typeclass.
The use of a specific encoding also suggests other possible encodings, using different monoids. For example,
if we use the Integer type, which can handle arbitrarily large signed numbers, then this will work as a possible
encoding. If we were to use Int64, on the other hand, we could encode some very large naturals, or at
least, we couldn’t distinguish them because of overflow.
We could also consider different typeclasses instead of Monoid, and get different interesting structures. As
alluded to in a side-note about category theory, if we have Group g => g -> g, we get the integers $\mathbb{Z}$.
It’s simple to replace this with more specialized algebraic classes, or classes having nothing to do with algebra at all.
Which encoding to use?
The answer, as alluded to before, is none of these. Really, if you need to do calculations involving these, you should use something like:
newtype Nat = Nat Integer
Making use of Haskell’s efficient arbitrarily large number type. But, these other encodings are interesting in terms of exploring the properties that define natural numbers. The last one, in particular, is a very elegant characterization of the natural numbers, not only in how natural it makes the operations on natural numbers seem, but also in how it generalizes effortlessly to other concepts. Scott encoding seems a bit pointless, but there are some cases where it improves performance. The scott encoding of free monads, for example, is actually more efficient in practice, thanks to GHC’s ability to aggressively inline closures.
These are the 3 most fundamental ways I know of encoding the naturals, but I do wonder if there might be more…